
Alta Disponibilidade de Rede para ISP’s
José Maurício dos Santos Pinheiro
Professor Universitário e Consultor Técnico
As redes de comunicação estão disponíveis para todos, com sistemas maduros e capazes de atender as necessidades particulares de cada pessoa e cada negócio. Neste contexto, a disponibilidade dos serviços e a integridade das informações das redes dos provedores de serviços de Internet (ISP’s) são aspectos que interferem diretamente no atendimento dos usuários e nos custos do próprio negócio. Uma rede de comunicação é avaliada por sua disponibilidade, exige conhecimento técnico, manutenção permanente, atendimento a rígidos requisitos de segurança, o que demanda investimentos em financeiros e em pessoal.
1. Missão Crítica
A “missão” de uma rede ou sistema corresponde ao período de tempo no qual esta rede deve desempenhar corretamente suas funcionalidades, sem interrupções. Por exemplo, uma empresa que utilize um serviço de Internet no horário entre 8h e 20h, não pode ter seu sistema fora do ar durante este período de tempo. Já uma empresa que utilize o serviço de Internet 24h por dia obviamente apresenta uma necessidade contínua, de forma que qualquer tipo de parada deve ser evitado.
Assim, pode-se resumir “missão crítica” como a operação 24 x 7 (24 horas por dia, 7 dias por semana) dos sistemas já considerando a possível falha de algum dispositivo da rede. Nessa categoria são enquadrados os servidores, roteadores, firewalls e todos os equipamentos que tenham uma atuação sistêmica na rede. O que determina qual tecnologia e os equipamentos que serão usados nesse ambiente é o nível de importância dos sistemas para os usuários e para a operação do negócio.
2. Disponibilidade
A configuração e manutenção, o controle e a gestão do hardware e do software em redes de comunicação são atividades dotadas de graus de complexidade variáveis e diferentes. Podem ocorrer erros na operação, inconsistências de bases de dados, interrupções inesperadas, problemas de instabilidade e falhas de segurança, que afetam o funcionamento da rede. Neste caso, é importante considerar dois aspectos: o tempo de disponibilidade (uptime) e o tempo de indisponibilidade, onde o sistema está fora de uso (downtime).
O período de uptime é o intervalo de tempo entre o fechamento de um chamado anterior e o início da próxima falha. Já o período de downtime se inicia com a abertura do chamado de reparo (trouble-ticket), que marca o reconhecimento da indisponibilidade da rede, e termina com o reparo realizado e o fechamento do chamado, após o reconhecimento da estabilização do sistema conforme mostra a Figura 1.
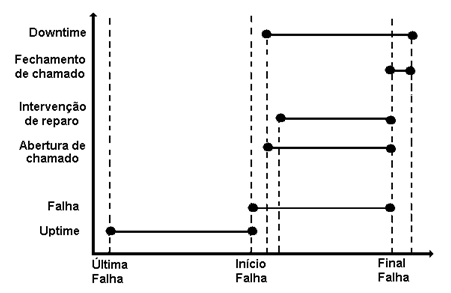
Figura 1 – Delimitação do Uptime e Downtime
O período de downtime serve de base para o cálculo para determinar dois momentos de disponibilidade do sistema: a disponibilidade total, que corresponde ao período de operação regular da rede e a disponibilidade percebida, que corresponde à disponibilidade dos serviços, percebida pelos usuários, medida a partir dos registros de chamados abertos junto ao help desk.
3. Classes de Disponibilidade
A disponibilidade de uma rede pode ser enquadrada normalmente em três classes, de acordo com uma faixa de valores percentuais: Disponibilidade Básica, Disponibilidade Contínua e Alta Disponibilidade.
3.1. Disponibilidade Básica
É aquela encontrada em redes desprovidas de algum mecanismo especial para redundância ou contingência de software ou hardware, que vise mascarar as eventuais falhas da rede. Sistemas nesta classe apresentam disponibilidade de 99,0% a 99,9%. Isto equivale a dizer que em um ano de operação a rede pode ficar indisponível por 8,76 horas a 3,65 dias. Convém ressaltar que nessa classe os tempos de indisponibilidade não levam em consideração a possibilidade de paradas planejadas para troca de equipamentos, por exemplo.
3.2. Disponibilidade Contínua
Uma disponibilidade com valores mais próximos de 100% representa um menor tempo de inatividade da rede, de forma que os valores de indisponibilidade são desprezíveis. Neste caso, os sistemas em uso são conhecidos como tolerantes a falhas “fault tolerance”, já que o uptime corresponde a valores de aproximadamente 99,99999%, ou seja, os sistemas funcionam, no mínimo, por aproximadamente 8759 horas (de 8760) por ano. Em sistemas desse tipo, sempre há redundância de recursos, ou seja, se um dispositivo de rede crítico deixa de funcionar, um segundo assume imediatamente a sua função.
Todas as paradas planejadas e não planejadas são mascaradas e o sistema é considerado sempre disponível.
3.3. Alta Disponibilidade
Entende-se por sistema de alta disponibilidade ou “high availability” aquele insensível a falhas de software, de hardware e de energia elétrica. Em sistemas desse tipo os equipamentos são desenvolvidos para oferecer o menor risco de falhas possível. Adicionando-se mecanismos de detecção, recuperação e mascaramento de falhas, pode-se aumentar a disponibilidade de modo que este venha a se enquadrar como de alta disponibilidade.
Na classe de alta disponibilidade encontram-se as redes que apresentam valores tipicamente na ordem de 99,99% a 99,9999%. Uma aplicação de alta disponibilidade pode ser projetada para suportar paradas planejadas, o que pode ser importante, por exemplo, para permitir a atualização de hardware ou software por problemas de segurança (atualização de interfaces, patches, por exemplo), sem que o serviço deixe de ser prestado. Aqui se encaixam grande parte das aplicações dos ambientes das operadoras de telecomunicações.
A Tabela 1 apresenta as três classes de disponibilidade e relaciona os valores de disponibilidade anual, indisponibilidade anual e indisponibilidade mensal.

4. Confiabilidade da Rede
A confiabilidade da rede é tanto melhor quanto maior for o tempo de operação livre de falhas ou tempo médio entre falhas – MTBF (Mean Time Between Failures) em relação ao tempo de disponibilidade total da rede, assim como quanto menor for o tempo de paralisação decorrente de falhas, definido como tempo médio para reparo – MTTR (Mean Time To Repair).
O MTBF é designado para expressar o tempo médio entre interrupções de serviço (tempo entre falhas), considerando que uma rede é um serviço e não um componente. Já o MTTR se refere ao tempo transcorrido para o reparo de um serviço (tempo para reparo), conforme ilustra a Figura 2.
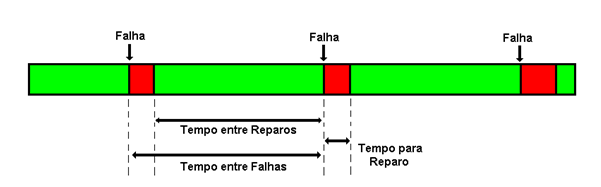
Figura 2 – MTBF e MTTR
Os valores de disponibilidade (A) de um sistema podem ser obtidos de maneira simplificada a partir da fórmula:
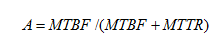
O MTTR associado ao MTBF mede a confiabilidade do sistema. Como nos sistemas de alta disponibilidade o MTBF é muito maior que o MTTR, a confiabilidade (N) pode ser definida percentualmente, de forma simplificada, por:
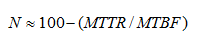
5. Escalabilidade da Rede
Escalabilidade é a possibilidade de uma rede expandir sua capacidade de transmissão conforme as necessidades, algo muito comum em telecomunicações. Antes de tudo, é necessário avaliar quais as tendências de aumento no uso dos recursos da rede e, a partir daí, deve-se criar condições para que essa capacidade seja aumentada conforme a real necessidade do negócio.
Quando a capacidade de tráfego do sistema aproxima-se da sua utilização máxima (a capacidade da rede em uso é chamada de “utilização”), podem ocorrer atrasos na transmissão da informação ocasionando o que conhecemos por “congestionamento” e, conseqüentemente, a vazão de dados diminui. Embora atraso e congestionamento sejam tópicos diferentes, existe uma relação entre eles que permite estimar a quantidade do atraso a partir do percentual da capacidade da rede que está sendo usada. O atraso efetivo em um sistema pode ser determinado pela seguinte relação:
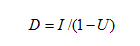
Onde:
D = atraso efetivo;
I = atraso da rede quando o meio de transmissão está vazio;
U = utilização.
Quando não há tráfego, o valor de U é zero, assim o atraso efetivo é equivalente ao atraso da rede. Com o aumento do tráfego, a utilização aumenta e o atraso efetivo fica maior. Uma utilização aceitável depende da finalidade do projeto e das necessidades relacionadas. Entretanto, uma rede de comunicação não deve operar com nível de utilização igual ou superior a 90%. Assim, é importante prever soluções para que os sistemas não parem de funcionar apenas por falhas ou erros, mas também que não sejam paralisados por sobrecarga. Se, por exemplo, um servidor estiver apto a receber mil solicitações de conexão por hora, é necessário observar se esse limite não está sendo atingido. Se isso ocorrer, deve-se aumentar sua capacidade, caso contrário, o servidor ficará sobrecarregado e poderá ficar indisponível para os usuários. Por outro lado, é necessário cuidado para não superdimensionar os sistemas dotando-os de uma alta capacidade que não será usada o que irá influenciar nos custos operacionais.
6. Tolerância a Falhas e Alta Disponibilidade
Para se entender exatamente o que é a tolerância a falhas e alta disponibilidade de rede, o ISP deve conhecer três conceitos básicos envolvidos e muitas vezes utilizados tecnicamente de forma errônea: falha, erro e defeito. São palavras que parecem sinônimas, mas que na verdade designam a ocorrência de algo anormal em três universos diferentes da rede de comunicação:
- Falha – ocorre no universo físico, ou seja, no nível mais baixo do hardware de rede. Uma flutuação de energia da fonte de alimentação, rompimento de um cabo ou interferência eletromagnética em RF são exemplos de falhas. Em geral, são eventos indesejados que afetam o funcionamento da rede ou partes dela;
- Erro – A ocorrência de uma falha pode acarretar um erro, que é a representação da falha no universo do sistema. Uma falha pode fazer com que um (ou mais de um) equipamento altere seu comportamento inesperadamente, o que afetará o funcionamento da rede representando lentidão, perda de pacotes, interrupção de serviço nos usuários;
- Defeito – a informação errônea, se não for percebida e tratada rapidamente poderá gerar o que se conhece por defeito. O sistema simplesmente apresenta funcionamento inconstante, baixo throughput, delay, taxa de erros, entre outros. Requer agora a interação de vários profissionais e poderá trazer desconforto com os usuários envolvidos.
Observa-se então que uma falha no universo físico pode causar um erro no universo do sistema, que por sua vez pode causar um defeito percebido no universo do usuário. O princípio de tolerância a falhas visa exatamente resolver as falhas ou tratá-las enquanto ainda são erros. Já o princípio da alta disponibilidade admite que as máquinas falhem ou apresentem defeito, contanto que exista outro equipamento para assumir sua funcionalidade no sistema. Entretanto, para que um equipamento assuma as funcionalidades de outro é necessário que existam meios que permitam a localização da falha. Isso pode ser conseguido através de testes periódicos nos quais os sistemas redundantes verificam não apenas se os sistemas principais estão ativos, mas também se estão fornecendo respostas adequadas às requisições de serviço dos usuários.
Neste ponto, é importante observar que mecanismos de detecção configurados incorretamente podem causar instabilidades no sistema com a entrada e saída de funcionamento dos equipamentos devido a “falsos positivos”, quer dizer, detecta-se um mau funcionamento no sistema que não ocorreu de fato. Por outro lado, notar também que, pelos testes serem periódicos, existe um intervalo de tempo durante o qual o sistema principal pode estar indisponível sem que o sistema redundante reconheça essa falha ocasionando um “falso negativo”.
7. Estruturando a Rede com Disponibilidade
Há várias formas de um ISP estruturar sua rede de comunicação com a disponibilidade necessária, variando de acordo as necessidades das aplicações, infraestrutura, recursos financeiros disponíveis etc. As alternativas podem ser combinadas para aumentar a disponibilidade da rede, entre elas destacam-se:
7.1. Redundância
Inclui a redundância de interfaces de rede, de fontes de alimentação, de processadores, de links de comunicação e de servidores. A redundância é um recurso primordial, pois no caso de falha de algum dispositivo, o sistema continua funcionando normalmente. Na Figura 3, o exemplo da redundância dos servidores de backbone de rede.
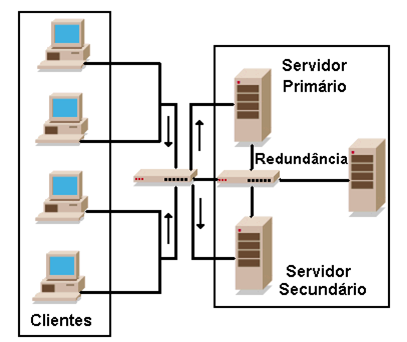
Figura 3 – Redundância
7.2. Failover
Trata-se do processo no qual uma máquina assume os serviços de outra, quando esta última apresenta falha; pode ser automático ou manual. Dependendo da natureza da operação, executar um failover significa interromper as transações em andamento, perdendo-as, sendo necessário reiniciá-las após o processo. Em outros casos, significa apenas um retardo até que o serviço esteja novamente disponível. Nota-se que o failover pode ou não ser um processo transparente, dependendo da aplicação envolvida.
7.3. Failback
É o processo de retorno de um determinado serviço de outra máquina para a máquina de origem após um failover. Também pode ser automático, manual ou até mesmo não desejado (em alguns casos, em função da possível nova interrupção na prestação no sistema, o failback pode não ser atraente). Na Figura 4, um exemplo de failover, quando o servidor primário de DNS, por exemplo, apresenta problemas e a funcionalidade do sistema é mantida pelo servidor secundário até seu reparo.
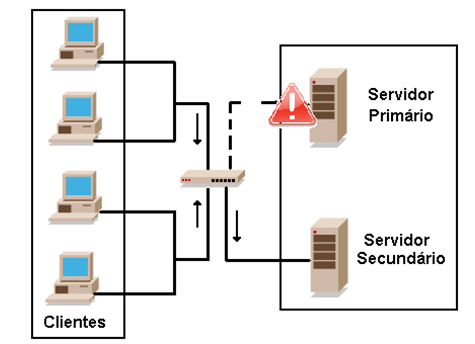
Figura 4 – Failover e Failback
7.4. Load Balance
O Load Balance (balanceamento de carga) é usado para evitar “gargalos” de CPU, de acesso aos sistemas ou mesmo à rede. Pode-se lançar mão dessa técnica nos roteadores de núcleo da rede para distribuir a carga de acesso às aplicações de maneira uniforme conforme a Figura 5.
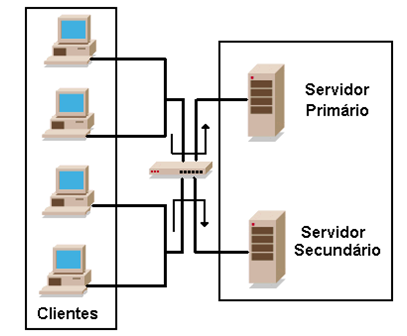
Figura 5 – Load Balance
8. Implantando Alta Disponibilidade
A real necessidade de implantar um sistema com alta disponibilidade depende das respostas a algumas perguntas. Se as respostas a elas forem positivas e o tempo de parada aceitável for de apenas alguns minutos, é altamente indicado o projeto para alta disponibilidade no ambiente da rede:
- Qual é o prejuízo de uma parada não programada de um sistema importante para os usuários devido a um incidente de segurança?
- O investimento para projetar, instalar e manter uma infraestrutura paralela de redundância justifica os custos operacionais?
- Qual o tempo de interrupção dos sistemas considerado aceitável pelos usuários?
- Os serviços disponibilizados pela rede corporativa são essenciais ao negócio?
Diagnosticada a necessidade de alta disponibilidade, o próximo desafio é como estruturar este ambiente. Escolher a estratégia que irá nortear o processo é crucial para o sucesso do projeto. Mapear a infraestrutura envolvida nos processos de negócio, aqueles sem os quais a rede poderia parar, detalhando cada componente da solução a fim de entender qual a importância de cada um no conjunto é fundamental.
8.1. Aspectos de Segurança
Para construir o ambiente de alta disponibilidade não basta apenas cuidar dos recursos que farão parte do sistema, mas também de toda a infraestrutura necessária (instalações prediais, energia elétrica, controle de acesso, climatização, sistemas de incêndio, entre outros). Por exemplo, contar com uma alimentação elétrica confiável é um desafio permanente os provedores, os quais necessitam de energia limpa e contínua para maximizar a disponibilidade e eficiência de suas redes. No complemento ou substituição da energia fornecida pela concessionária é possível contar com redundância no fornecimento de energia elétrica, seja através de UPS (Uninterruptible Power Supply) ou de GMG (Grupo Motor Gerador), bem como sistemas de comunicação redundantes e integrados, garantindo a operação da rede mesmo na ocorrência de situações adversas. Entretanto, antes de investir nestes recursos, é importante executar um levantamento da situação atual a fim de identificar e definir as prioridades de ação, algo fundamental no processo de conquista da alta disponibilidade da rede.
Os riscos de segurança são identificados através de uma metodologia apropriada para a avaliação dos processos, das pessoas e da própria tecnologia envolvida. Os custos do projeto precisam ser analisados e confrontados com prováveis prejuízos resultantes de falhas, conforme exemplifica a Figura 6.

Figura 6 – Metodologia de análise de riscos
Dentre os diversos pontos que requerem análise de segurança destacam-se:
- Identificar, analisar e classificar os riscos relacionados à segurança da informação e ao negócio segundo as prioridades definidas;
- Planejar e agendar as atividades necessárias;
- Agir estrategicamente na solução dos problemas relacionados aos sistemas e processos vulneráveis;
- Minimizar os riscos de parada nos serviços de TI e as perdas em casos de incidentes de segurança através de um controle efetivo;
- Registrar o aprendizado com as ações anteriores e manter uma documentação atualizada de todos os procedimentos.
O processo de avaliar riscos e selecionar controles deve ser executado tantas vezes quanto necessário e revisões devem ser feitas em diferentes níveis de profundidade, dependendo dos resultados das avaliações anteriores e das mudanças nos níveis de riscos que a estrutura da rede está preparada para aceitar.
9. Conclusões
O planejamento de sistemas de comunicação de alta disponibilidade é estratégico para um provedor quando o faturamento e o relacionamento com seus clientes e fornecedores dependem desse recurso. Neste aspecto, os prejuízos financeiros oriundos da indisponibilidade dos sistemas podem não ser o único efeito colateral. Mais do que a perda financeira, muitas vezes a imagem da empresa é prejudicada por conta da instabilidade ou indisponibilidade dos recursos perante seus colaboradores e clientes. Portanto, acompanhar o desempenho da infraestrutura envolvida é essencial ao sucesso do negócio.
10. Referências Bibliográficas
- ALGER, Douglas. Build the Best Data Center Facility for Your Business. Cisco Press: Indianapolis, 2005.
- Jayaswal, Kailash. Administering Data Centers: Servers, Storage, and Voice over IP. Indianapolis: Wiley Publishing, Inc., 2006.
- PINHEIRO, José M. Infra-estrutura Elétrica para Redes de Computadores. Rio de Janeiro: Livraria Ciência Moderna, 2008.
- PRESTON, W. Backup & Recovery. Sebastopol: O’Reilly, 2006.
- Roth, Kurt W.; Goldstein, Fred; Kleinman, Jonathan. Energy Consumption by Office and Telecommunications Equipment in Commercial Buildings – Volume I: Energy Consumption Baseline. Cambridge: Arthur D. Little, Inc., 2002.
- SILVA, Pedro Tavares; CARVALHO, Hugo; TORRES, Catarina Botelho. Segurança dos Sistemas de Informação. Lisboa: Centro Atlântico, 2003.
- TANENBAUM, Andrew. Redes de Computadores, 4 ed. Rio de Janeiro: Campus, 2005.




Sou a Valéria da Silva, gostei muito do seu artigo tem
muito conteúdo de valor, parabéns nota 10.
Visite meu site lá tem muito conteúdo, que vai lhe ajudar.